

AI人工智能综合解决方案提供商
专注GPU集群计算网络、存储网络最佳实践设计。擅长深度学习训练模型部署与参数调优。提供HPC/GPU/英伟达解决方案销售
算力集群架构设计
以GPU服务器为核心,通过计算网络与存储网络的最佳实践设计,帮助用户实现分布式并行高效训练。

模型部署与调优服务
针对DL、NLP等领域,基于LLM、Stable Diffusion等模型特点,提供优化过的Pre-trained Model与商业SDK

一站式软硬件采购
提供HPC/英伟达GPU | HGX | OVX | 专业图形工作站/元宇宙全栈软硬件一站式采购。

方案设计
基于用户真实的Workload,提供GPU算力集群,IB组网,高性能+大容量存储,AI集群管理平台等一整套解决方案设计与咨询服务。

性能调优
如:指导安装NVIDIA-Nemo Megatron,调试训练流程卡住不动问题,排除Nemo-Megatron 出现报错问题及安装Apex后显示报错问题等

代建代维
按照订阅式服务模式,企业支付技术服务费,宽恒信息提供全栈硬件、软件、算法工程师、IDC运维服务。(具体细节另行协商)
数据中心解决方案
从 AI 和数据分析,到高性能计算 (HPC),再到渲染,数据中心都是攻克某些重要挑战的关键。端到端的 NVIDIA 加速计算平台对硬件和软件进行了集成,可为企业构建强大而安全的基础设施蓝图,支持在所有现代化工作负载中实施开发到部署的操作。

从云……
借助基于云的 GPU 解决方案,企业可以随时随地访问高密度计算资源和功能强大的虚拟工作站,而无需构建实体数据中心。

到办公室……
无论是通过虚拟桌面、应用、工作站,还是云端的优化容器,数据科学家、研究人员和开发者都可以在自己的办公桌上为经 GPU 加速的 AI 和数据分析提供支持。

到数据中心……
GPU 加速的数据中心可凭借更少的服务器,为各种规模的计算和图形工作负载提供出色性能,从而让您能更快地获取见解并大幅降低成本。这类数据中心不仅可以存储、处理和分析敏感数据,还能维护操作的安全性。

再到边缘端
边缘 AI 需要一个可扩展的加速平台,该平台能够实时推动决策,并让各个行业都能在行动层面(商店、制造工厂、医院和智慧城市)实现自动化智能。
扩散模型是一个系统,由几个组件和模型构成,而非单独一个模型。

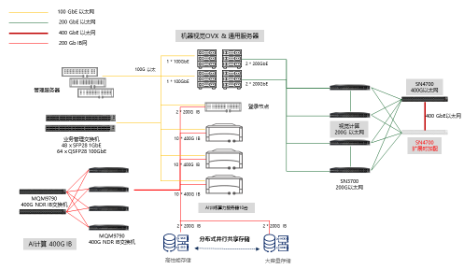
AI计算与视觉计算混合异构的高性能智算解决方案
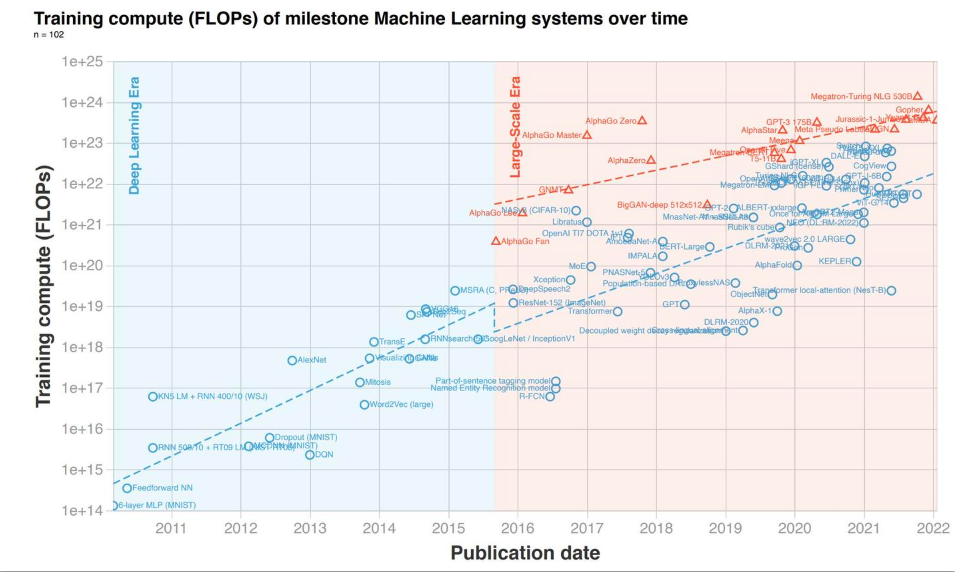
Transformer引入了全注意力机制,通过矩阵乘使得LM模型SOTA,进入LLM时代
打造未来工厂宝马集团


数据分析、机器学习、深度学习训练、深度学习推理、预测与预报





